Présentation
Collatinus est une application libre, gratuite et multi-plateforme (Mac, Windows, Ubuntu et Debian GNU/Linux), simple à installer et facile à utiliser.
Collatinus est à la fois un lemmatiseur et un analyseur morphologique de textes latins : il est capable, si on lui donne une forme déclinée ou conjuguée, de trouver quel mot il faudra chercher dans le dictionnaire pour avoir sa traduction dans une autre langue, ses différents sens, et toutes les autres données que fournit habituellement un dictionnaire.
En pratique, il est utile surtout au professeur de latin, qui peut ainsi très rapidement, à partir d’un texte hors-manuel, distribuer à ses élèves un texte inédit avec son aide lexicale. Les élèves s’en servent souvent pour lire plus facilement le latin lorsque leurs connaissances lexicales et morphologiques sont encore insuffisantes.
Principales fonctionnalités
- lemmatisation de mots latins ou d'un texte latin entier,
- traduction des lemmes grâce aux dictionnaires de latin incorporés dans l'application,
- affichage des quantités (durée longue ou brève des syllabes) et des flexions (déclinaison ou conjugaison).
Aide
Atouts de Collatinus
- efficacité de la lemmatisation (~1000 mots/s. ; dépend bien sûr de la machine sur laquelle le programme tourne),
- lemmes extraits du Lewis & Short 1879 et du Gaffiot 2016 (avec l'autorisation de l'auteur) avec les traductions en anglais et en français. Collation avec ceux issus du Georges 1913 et du Jeanneau 2017 (avec l'autorisation de l'auteur),
- lexique de base de 24 155 lemmes (textes classiques du LASLA) et extension de 58 384 lemmes auxquels s'ajoutent quelques variantes graphiques et l'assimilation du préfixe,
- classement des lemmatisations et des analyses morpho-syntaxiques en fonction du nombre d'occurrences observé dans les textes du LASLA,
- traductions d'environ 11 000 lemmes dans 6 langues différentes, autres que le français et l'anglais (à améliorer)
- possibilité de coloriser un texte en fonction d'une liste de mots connus,
- scansion et accentuation d'un mot ou d'un texte,
- tagueur probabiliste basé sur les statistiques faites sur les textes du LASLA (~1 800 000 mots)
- consultation de dictionnaires en mode texte ou image (djvu). Facilité d'ajout de nouveaux dicos (djvu),
- possibilité de consulter Collatinus depuis un autre programme (par exemple, LibreOffice) via un port interne,
- possibilité d'interroger Collatinus à partir d'un client en mode console. Lemmatisation d'un texte à partir d'un fichier
- code source du logiciel organisé en modules de manière à faciliter le développement d'applications plus spécifiques
Historique
Collatinus était destiné, à l'origine, à produire des documents sur papier, et c'est encore souvent dans ce but que je l'utilise. J'ai commencé à le perfectionner quand je me suis aperçu que de nombreux utilisateurs s'en servaient à d'autres fins :
- disposer, lorsqu'on lit un texte latin, d'une aide lexicale et morphologique immédiate et discrète,
- faire des recherches lexicales et stylistiques,
- donner aux élèves des tâches d'identification, de relevé, de transformation.
Principes de fonctionnement
Contrairement à la majorité des lemmatiseurs qui utilisent une liste de formes fléchies, Collatinus utilise un lexique contenant les lemmes et les informations nécessaires pour leur flexion. L'avantage est qu'avec 11 000 lemmes, Collatinus est capable de reconnaître plus d'un demi-million de formes. L'ajout du lemme correspondant à une variante orthographique (médiévale, par exemple) permettrait également de reconnaître toutes ses formes fléchies.
A partir du lemme et des désinences qui lui sont associées, Collatinus peut aussi donner des tableaux de flexion qui peuvent être utiles lors de l'apprentissage du latin.
Enfin, lorsque les quantités sont connues pour le lemme, Collatinus peut scander le mot et par là même tout un texte. Lorsqu'il scande un texte, Collatinus applique les règles habituelles d'allongement et d'élision.
Le lexique a d'abord été constitué au fil des années par les utilisateurs de Collatinus. Il a ensuite été complété par un dépouillement systématique des dictionnaires numériques (qui sont par ailleurs consultables dans Collatinus). Il compte environ 82 000 lemmes (et probablement quelques erreurs et de nombreux doublons, en particulier avec les formes grecques en -os qui coexistent avec la forme latinisée en -us). Afin d'optimiser le temps de chargement du programme, le lexique a été divisé en deux parties inégales. Le lexique de base compte environ 24 000 lemmes et devrait permettre de lemmatiser une bonne partie de la littérature classique. L'extension du lexique (58 000 lemmes) contient pour sa part des mots peu usités. Bien évidemment, le programme peut encore achopper sur les mots les plus rares ou sur les formes irrégulières.
Nouveautés
La version actuelle de Collatinus, numérotée 11.2, apporte son lot de nouveautés et d'améliorations :
- possibilité d'exporter les résultats de lemmatisation ou de tagage au format CSV
- récupération de quelque 13 000 traductions anglaises
- documentation de la partie serveur de Collatinus (en français seulement)
- prise en compte des alphabets non-latins avec un ordre alphabétique différent, y compris avec des digrammes, pour la consultation des dicos en djvu (si on veut, par exemple, ajouter un dictionnaire Tchèque-Latin). Possibilité de prendre en compte des caractères de même rang, par exemple ph=f et y=i, toujours en djvu
- corrections de bugs :
- l'interface en anglais est maintenant fonctionnelle
- la lemmatisation et la traduction des mots censés être connus (lors de la colorisation d'un texte) ne sont plus données. On peut récupérer les nombres d'occurrences (donc l'utilisation) des mots connus.
La version 11 (bêta), sortie en juin 2017, a ajouté de nombreuses fonctionnalités au logiciel :
- lexique "complet" (85 000 entrées)
- rangement des lemmatisations d'une forme en fonction des fréquences
- consultation du Gaffiot 2016 (Gréco)
- possibilité de consulter deux pages de dictionnaire simultanément (synchronisées ou non)
- simplification de l'installation des dictionnaires
- possibilité d'accentuer les textes (et de marquer les syllabes)
- possibilité de coloriser les textes en fonction d'une liste de mots connus
- ajout d'un tagueur probabiliste qui tient compte du contexte (tags) pour trouver la lemmatisation "la plus probable"
- serveur sur un port interne qui permet une utilisation en ligne de commande avec la possibilité d'interroger Collatinus sans quitter son traitement de texte
Captures d'écran
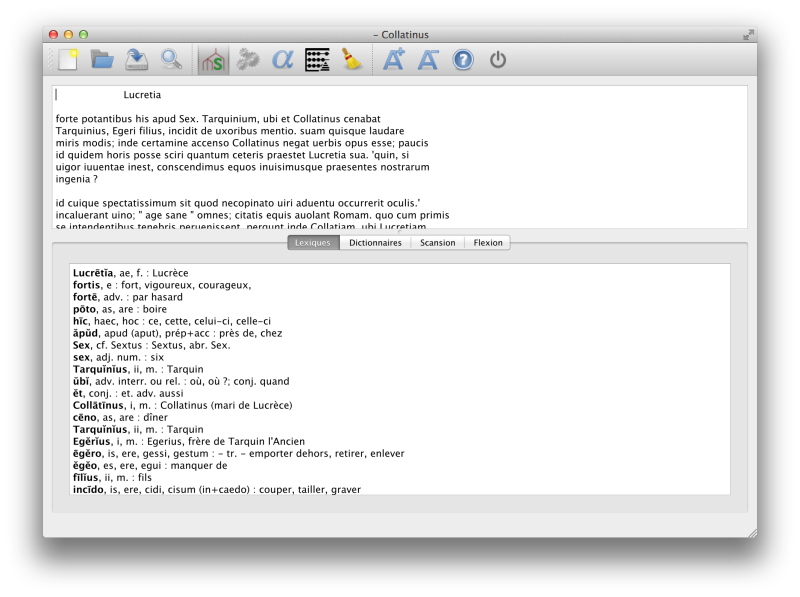
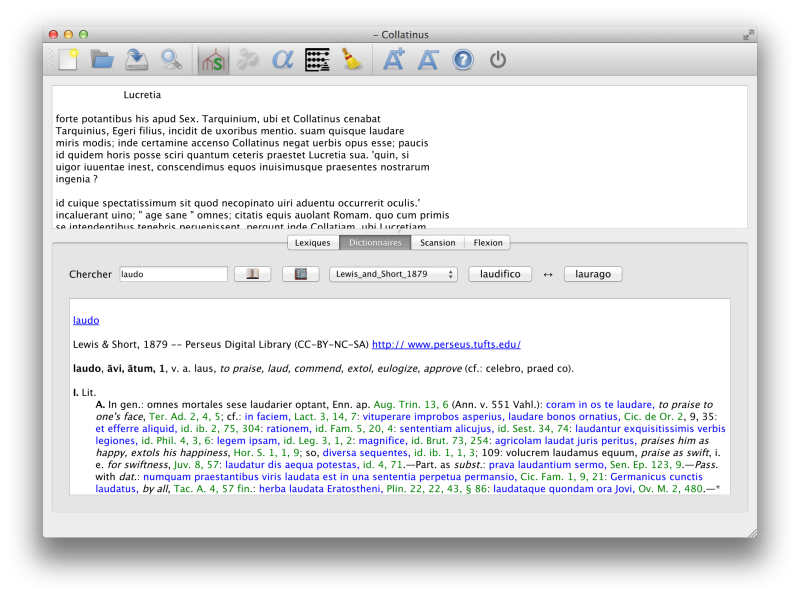
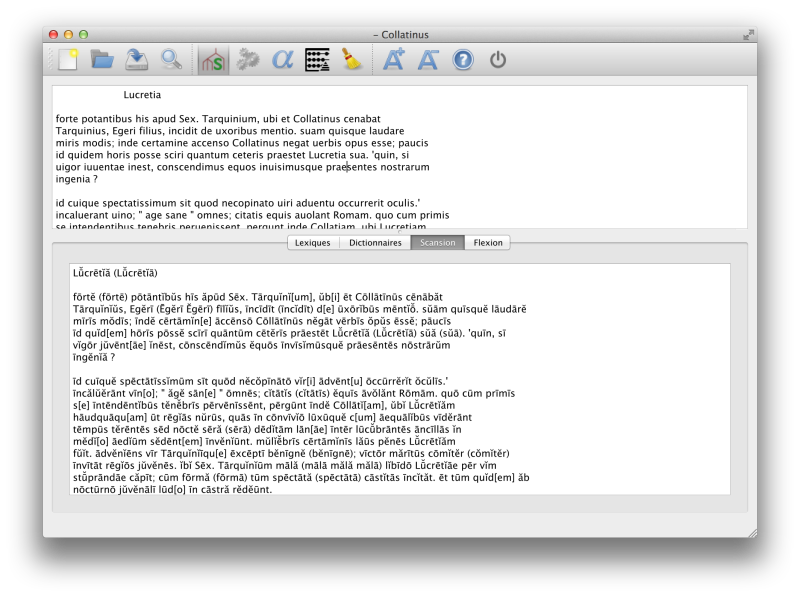
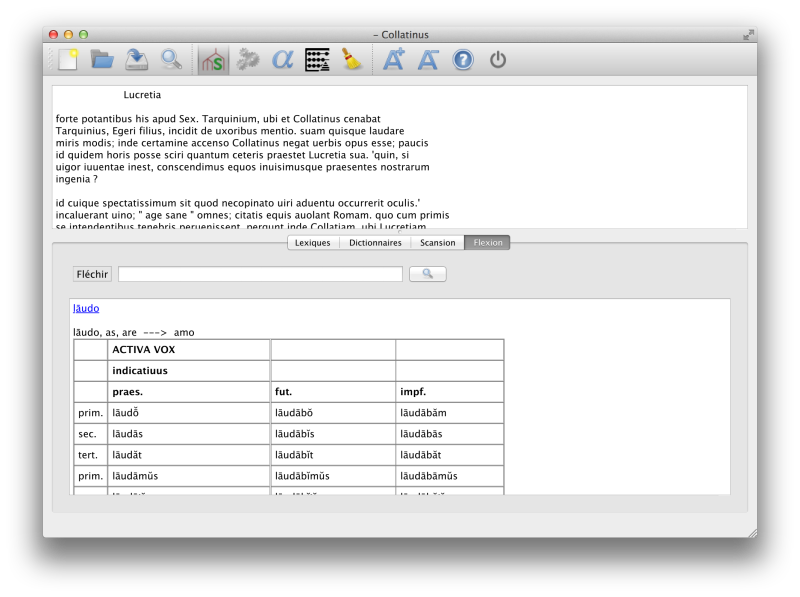
Téléchargements
Collatinus est proposé en trois versions, qui se distinguent par le nombre de dictionnaires pré-installés :
- complète (9 dictionnaires)
- intermédiaire (5 dictionnaires)
- minimale (2 dictionnaires)
Ces versions peuvent être complétées à tout moment en téléchargeant un ou plusieurs dictionnaires proposés ci-dessous et en les installant depuis le menu Extra de Collatinus.
Dictionnaires
Les dictionnaires suivants sont compatibles avec la version 11 et supérieure de Collatinus.
En mode texte :
- Gaffiot 2016 (15 Mo — latin-français)
- Jeanneau 2017 (12 Mo — latin-français)
- K. E. Georges 1913 (16 Mo — latin-allemand)
- Lewis & Short 1879 (22 Mo — latin-anglais)
- Lebaigue 1921 (223 Mo — latin-français)
- Du Cange 1883 (58 Mo — glossaire du latin médiéval)
- Köbler 2010 (34 Mo — latin médiéval-allemand) Nouveau
- Ramminger 2020 (9 Mo — néolatin-allemand) Nouveau
En mode image :
- Calonghi 1898 (62 Mo — latin-italien)
- De Miguel 1867 (153 Mo — latin-espagnol)
- Faria 1975 (171 Mo — latin-portugais) Nouveau
- Gaffiot 1934 (101 Mo — latin-français)
- Nöel 1851 (218 Mo — latin-français)
- Valbuena 1819 (86 Mo — latin-espagnol)
- Quicherat 1836 (303 Mo — prosodique français)
- Franklin 1867 (17 Mo — noms propres)
- Noël 1824 (21 Mo — étymologique des noms propres)
Collatinus 11.2 (version courante)
Version complète
(9 dictionnaires inclus)
- Lewis & Short, 1879 (latin-anglais)
- Gaffiot, 2016 (latin-français)
- Du Cange, 1883 (glossaire de latin médiéval)
- Georges, 1913 (latin-allemand)
- Jeanneau, 2017 (latin-français)
- Gaffiot, 1934 (latin-français)
- Calonghi, 1898 (latin-italien)
- Valbuena, 1819 (latin-espagnol)
- Quicherat, 1836 (latin-français)
Version intermédiaire
(5 dictionnaires inclus)
- Lewis & Short, 1879 (latin-anglais)
- Gaffiot, 2016 (latin-français)
- Du Cange, 1883 (glossaire de latin médiéval)
- Georges, 1913 (latin-allemand)
- Jeanneau, 2017 (latin-français)
Version minimale
(2 dictionnaires inclus)
- Lewis & Short, 1879 (latin-anglais)
- Gaffiot, 2016 (latin-français)
Sources
Toutes les versions (par système)
| Mac OS | Windows (32 bits) | Windows (64 bits) | GNU/Linux | |
|---|---|---|---|---|
| Version complète |
|
|||
| Version intermédiaire | ||||
| Version minimale |
Archives (versions antérieures)
Collatinus 11.1
Version complète (tous les dictionnaires inclus)
Version intermédiaire (5 dictionnaires inclus)
Version lite (2 dictionnaires inclus)
Sources
Collatinus 11 (bêta)
Version complète (tous les dictionnaires inclus)
Version intermédiaire (5 dictionnaires inclus)
Version lite (2 dictionnaires inclus)
Sources
Collatinus 10.2.2
Version standard (tous les dictionnaires inclus)
Version standard (tous les dictionnaires inclus)
Version lite (sans dictionnaire)
Sources
Toutes les versions (par langue de dictionnaire et par système)
| Mac OS | Windows | GNU/Linux | |
|---|---|---|---|
| Français (Gaffiot 1934) |
|
||
| Anglais (Lewis & Short 1879) | |||
| Allemand (K. E. Georges 1913) | |||
| Italien (Calonghi 1898) | |||
| Versions standard (4 dicos) |
Dictionnaires
- Gaffiot 1934 (djvu, 97 Mo)
- Lewis & Short 1879 (xml, 66 Mo)
- K. E. Georges 1913 (xml, 25 Mo)
- Calonghi 1898 (djvu, 60 Mo)
- Jeanneau 2013 (xml, 20 Mo)
- Valbuena 1819 (djvu, 82 Mo)
FAQ
- Mon Mac refuse d'ouvrir Collatinus en disant qu'il provient d'un développeur non identifié.
- Comment installer dans Collatinus un lexique ou un dictionnaire téléchargé depuis cette page ?
- Comment voir une page d'un dictionnaire en mode image sur Mac ?
- Je voudrais ajouter des lemmes dans le lexique de Collatinus. Où sont les données que Collatinus exploite ?
- Je souhaite ajouter un nouveau dictionnaire à Collatinus. Comment faire ?
- Collatinus ne reconnaît pas certains mots pourtant assez courants. Pourquoi ?
- Pour préparer les listes de vocabulaire pour mes étudiants, je voudrais supprimer les mots trop courants qu'ils connaissent. Collatinus peut-il le faire ?
- Comment lemmatiser un texte qui contient des graphies médiévales ?
- Mon Mac refuse d'ouvrir Collatinus en disant qu'il provient d'un développeur non identifié.
-
En effet Apple tend à privilégier l'utilisation de l'Apple Store et d'applications provenant de développeurs affiliés, dont Collatinus n'est pas. Le Mac refuse donc d'ouvrir une application téléchargée de provenance inconnue. Il s'agit là d'une précaution de sécurité qu'il est facile de contourner. La solution est donnée par Apple lorsque l'on clique sur le point d'interrogation qui figure dans la fenêtre pop-up d'avertissement. Il faut ouvrir l'application en passant par le menu contextuel : au lieu de faire simplement un double-clic sur l'application, on fera donc un "clic-droit" ou un "Ctrl-clic" (un clic en maintenant la touche Ctrl enfoncée) et dans le menu qui s'affiche, on choisira "Ouvrir". Une fenêtre d'avertissement similaire à la précédente s'affiche aussi, mais elle propose un bouton supplémentaire pour ouvrir malgré tout l'application. Cette manœuvre n'est nécessaire que lors de la première utilisation : les lancements suivants de Collatinus pourront se faire avec l'habituel double-clic.
Retrouver les instructions détaillées pour votre version de Mac OS sur le site support d'Apple.
- Comment installer dans Collatinus un lexique ou un dictionnaire téléchargé depuis cette page ?
-
Les dictionnaires ou les lexiques disponibles sur ce site sont dans un format compressé
.col. Ce format est reconnu par Collatinus qui décompressera le fichier téléchargé et installera tous les fichiers nécessaires là où il faut.Pour installer un dictionnaire ou un lexique, il faut procéder en deux temps :
On télécharge le (ou les) dictionnaire(s) (ou lexiques) que l'on souhaite installer.
En général, le navigateur propose spontanément d'enregistrer le fichier cible dans le dossier "Téléchargements" (ou équivalent, si la langue du système n'est pas le français). Parfois il faut avoir recours au clic-droit (ou Cmd-clic sur Mac avec un seul bouton) pour avoir accès au menu contextuel dans lequel on peut trouver "Enregistrer la cible du lien sous..." (ou une formulation équivalente). On notera soigneusement l'endroit où le fichier est enregistré.Dans Collatinus, on va dans le menu
Extraet on sélectionne l'entréeInstaller les dictionnaires téléchargésouInstaller les lexiques téléchargés. Apparaît alors une fenêtre qui vous demande de localiser le fichier ".col" que vous souhaitez installer. Si tout se passe bien, l'installation se termine avec un message de confirmation.
Pour que l'installation de nouveaux lexiques soit effective, il faut probablement quitter et relancer Collatinus. C'est inutile pour les dictionnaires, ceux-ci sont immédiatement consultables.
- Comment voir une page d'un dictionnaire en mode image sur Mac ?
-
Pour afficher une page d'un dictionnaire en mode image, Collatinus utilise un programme externe qui convertit une page du fichier Djvu en une image Tiff. Il faut donc installer l'utilitaire DjVuLibre (libre et gratuit) que l'on trouvera sur SourceForge : http://sourceforge.net/projects/djvu/files/
L'installation est standard et une application DjView (ou DjView.app) doit apparaître dans le dossier
Applications. Vous êtes alors prêt pour consulter le dictionnaire dans Collatinus. - Je voudrais ajouter des lemmes dans le lexique de Collatinus. Où sont les données que Collatinus exploite ?
-
Sous Windows, toutes les données sont dans le répertoire
data/à côté de l'exécutableCollatinus.exe. Sur un Mac, elles sont un peu plus cachées. Pour les voir, il faut commencer par "Afficher le contenu du paquet" avec un clic droit (ou ctrl-clic) surCollatinus.app. On avance alors dans l'arborescenceContents/MacOS/dataet là on trouve tous les fichiers qu'utilise Collatinus. Attention, à manipuler avec précaution !Si on veut ajouter des lemmes dans le lexique de Collatinus, on ouvrira
lemmes.laavec un éditeur de texte ou un tableur (le fichier est au format CSV avec le caractère "|" comme séparateur de champs). On se réfèrera à l'aide en ligne pour connaître l'usage des divers champs. Si toutes les données sont correctes, Collatinus sait fléchir ce nouveau lemme et reconnaître dans un texte toutes ses formes. Pour donner une traduction à ce nouveau mot, il faut intervenir dans leslemmes.*(lemmes.fr pour les traductions françaises).Des données erronées peuvent conduire à un comportement imprévisible. Si on prévoit de revenir souvent dans le répertoire
data/, on peut en faire un alias que l'on met à un endroit plus accessible et qui pointera vers l'emplacement souhaité. - Je souhaite ajouter un nouveau dictionnaire à Collatinus. Comment faire ?
-
Tout d'abord, il faut distinguer deux types d'objets différents qui correspondent au sens courant de dictionnaire :
- les lexiques : Collatinus les utilise pour reconnaître les formes fléchies et donner le sens du lemme correspondant. Ces fichiers sont nommés
lemmes.*et se trouvent dans le répertoiredata/. - les "vrais" dictionnaires (comme le Gaffiot, le Lewis & Short, etc...) : ces dictionnaires doivent être dans un format entièrement numérique XML/HTML (fichier .xml) ou dans un format image (fichier .djvu). Ils sont rangés dans le répertoire
data/dicoset sont accompagnés d'un fichier d'index (fichier .idx) et d'un fichier de configuration (fichier .cfg). Eventuellement complétés par un feuille de transformation (fichier .xsl) et/ou une feuille de style (fichier .css).
Aujourd'hui, avec la version 11, l'utilisateur peut ajouter tout seul des lexiques (ou des entrées dans les lexiques existants) ou des dictionnaires en djvu, à ses risques et périls. Pour que le programme reconnaisse un nouveau dictionnaire, les fichiers
mon_dico.cfgetmon_dico.idx, dans le répertoiredata/dicosà côté demon_dico.djvu, sont indispensables (etmon_dicone sera visible qu'après redémarrage du programme).
On s'inspirera des fichiers existants pour constituer le fichier .cfg ; l'item"debut="doit être un entier et indique le nombre de pages à sauter au début du fichier pour trouver le premier mot de l'index ; l'item"echelle="est aussi un entier (en %) et permet d'agrandir (ou rapetisser) l'image pour l'affichage à l'écran, par défaut l'échelle vaut 160.
Le fichier .idx contient l'index du dictionnaire et doit être constitué à la main. Il faut relever le premier mot de chaque page et le mettre, en minuscules, sur les lignes successives du fichier. Les mots doivent être en ordre alphabétique, ce qui est en général le cas pour un dictionnaire mais attention aux exceptions (certains placent le "ph" avec le "f" entre le "e" et le "g").Pour les dictionnaires en XML/HTML, la constitution de l'index doit passer par un programme et nécessite quelques manipulations trop complexes pour être décrites ici, mais nous pouvons le faire pour vous. Les règles générales pour le format du fichier .xml sont que chaque article occupe une seule ligne ou soit encadré par des balises spéciales (c'est-à-dire qui ne sont pas utilisées par ailleurs, par exemple
<item>...</item>ou<entryFree>...</entryFree>ou même<div>...</div>à condition qu'il n'y en ait pas d'autres), et que le lemme doit être facilement identifiable (par exemple, le premier mot entre des balises<H1></H1>ou l'attribut key de la balise EntryFree...). - les lexiques : Collatinus les utilise pour reconnaître les formes fléchies et donner le sens du lemme correspondant. Ces fichiers sont nommés
- Collatinus ne reconnaît pas certains mots pourtant assez courants. Pourquoi ?
-
Pour optimiser le démarrage du programme, le lexique que connaît Collatinus a été divisé en deux parties. Le lexique de base contient 24000 lemmes et il est systématiquement chargé. Il permet de lemmatiser beaucoup de textes classiques. Toutefois, si on va chercher des textes un peu "exotiques", ce vocabulaire classique peut être insuffisant. Il convient alors d'activer "l'extension du lexique" qui contient 58000 lemmes supplémentaires. Pour ce faire, on ira dans le menu
Lexiqueet on sélectionnera l'entréeExtension du lexique.Désactiver l'extension après l'avoir activée ne revient pas exactement à la situation initiale (avant la première activation). L'extension sera utilisée dans ce cas comme un "réservoir" d'information. Si une forme peut être lemmatisée avec le seul lexique de base, seules ces solutions seront proposées. Cela évite d'être "pollué" par des lemmatisations très improbables. En revanche, si le lexique de base ne suffit pas pour lemmatiser une forme, la recherche se fera aussi dans l'extension et toutes les solutions (s'il y en a) seront proposées.
- Pour préparer les listes de vocabulaire pour mes étudiants, je voudrais supprimer les mots trop courants qu'ils connaissent. Collatinus peut-il le faire ?
-
Quand on donne des listes de vocabulaire, il est souvent inutile de donner la traduction des mots trop courants comme "et", "cum" etc... Collatinus peut lire une liste de mots connus (menu
Fichier > Lire une liste de mots connus) qui est particulièrement facile à déterminer si les étudiants ont des listes de vocabulaire à apprendre. Une liste de mots connus est un fichier de type texte (.txt), contenant un seul mot par ligne. On trouvera un exemple de liste dans le fichier Exemple_liste.txt.zip. On peut évidemment définir autant de listes que l'on souhaite, une pour chaque niveau, par exemple. Remarque : les listes ne se cumulent pas, seule la dernière liste chargée est active (les précédentes sont effacées).L'effet de la lecture d'une liste de mots connus est double : lorsque l'on lemmatise un texte (dans la fenêtre supérieure de Collatinus), celui-ci est colorisé et les mots connus n'apparaissent pas dans la liste de vocabulaire (dans l'onglet "Lexique et morphologie" qui doit être actif). Le code couleur par défaut est :
- vert pour les formes dont le lemme est connu (c'est-à-dire dans la liste)
- noir pour les formes que Collatinus reconnaît mais qui relèvent de lemmes qui ne sont pas dans la liste de mots connus
- rouge pour les formes que Collatinus ne reconnaît pas.
Attention, quand un lemme est donné dans la liste de mots connus, il est implicitement supposé que l'étudiant connaît toutes les formes qui peuvent en découler. Par exemple, si "sum" apparaît dans la liste de mots connus, une forme un peu exotique comme "forent" sera supposée connue…
- Comment lemmatiser un texte qui contient des graphies médiévales ?
-
Dans la version 11.2 a été ajoutée une option expérimentale pour que Collatinus puisse reconnaître certaines graphies médiévales. Dans le menu
Lexique, on activera l'optionGraphies médiévales. Attention, cela peut introduire de fausses lemmatisations si on travaille sur un texte classique ou un texte dont la graphie a été "normalisée". On évitera donc soigneusement d'utiliser cette option sur des textes classiques.Le résultat de la lemmatisation ou de la scansion est classicisé : si le texte contient "celum", on obtiendra les lemmatisations "cāelŭm, cōelum, i, n.".
Cette option est toute nouvelle et seulement expérimentale. Nous espérons qu'elle puisse être utile à certains, mais il faut garder en tête que son utilisation n'est pas sans risque.
Crédits
Collatinus est développé par Yves Ouvrard, avec l'aide précieuse de Philippe Verkerk.
Il est publié sous licence GPL.
Remerciements : William Whitaker †, Jose Luis Redrejo, Georges Khaznadar, Matthias Bussonier, Gérard Jeanneau, Philippe Verkerk, Jean-Paul Woitrain, Philipp Roelli, Perseus Digital Library.